Results & Evaluation
Presented at AAAI25, the 39th Annual AAAI Conference on Artificial Intelligence, Philadelphia
We evaluated DPPL methods across multiple dimensions to comprehensively assess their performance:
Evaluation Dimensions
Tested across a range of privacy budgets from strict () to more relaxed () settings.
Evaluated on balanced (ratio=1) to highly imbalanced (ratio=100) datasets.
Tested with ViT-H-14, ViT-L-16, ViT-B-16, and ResNet-50.
Tested on CIFAR-10, CIFAR-100, STL10, and Food-101.
Dramatic Improvements for Underrepresented Classes
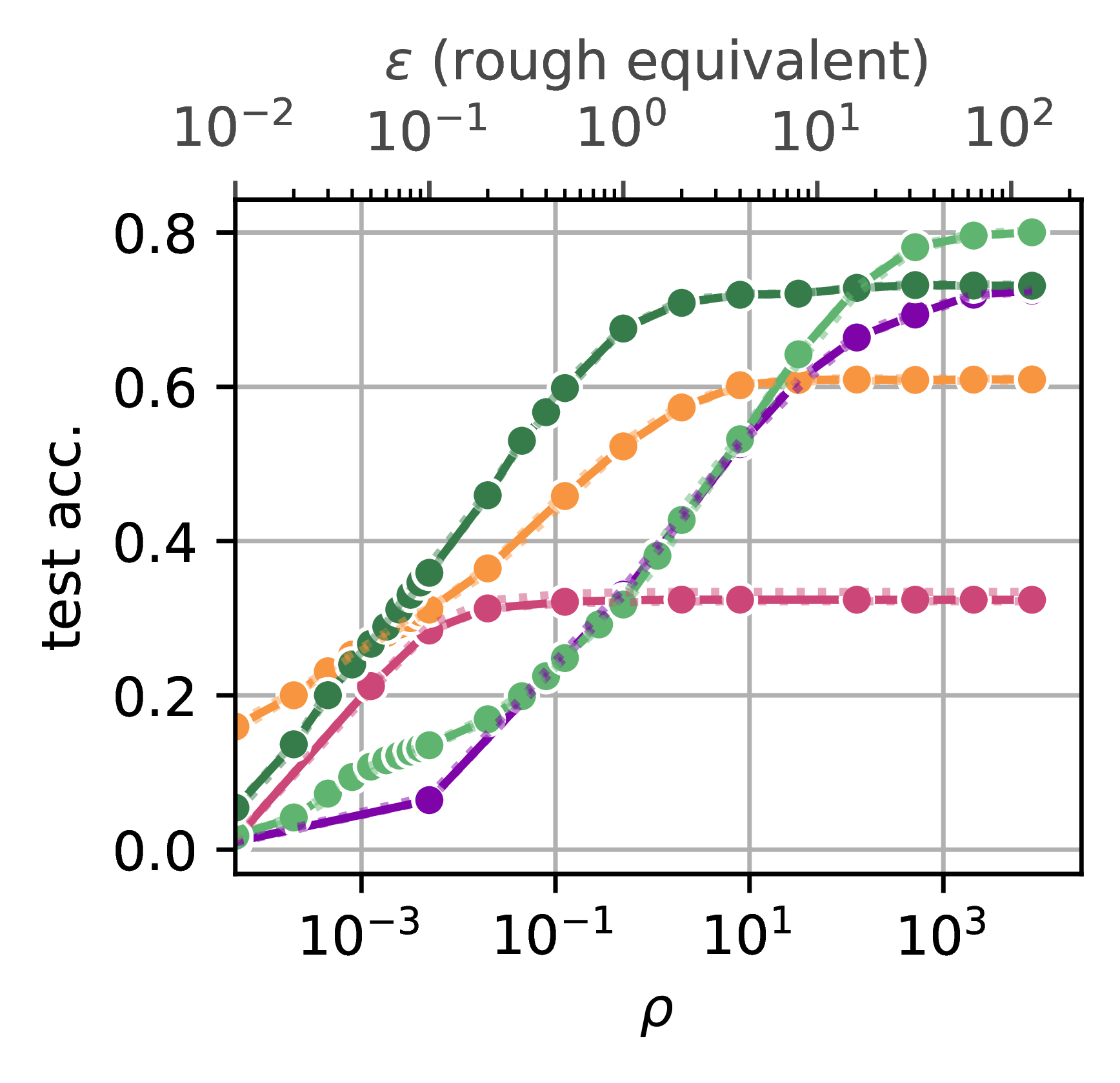
Our most striking result is the dramatic improvement for underrepresented classes at strict privacy budgets, e.g., :
- Classic DP-SGD: 0% accuracy on smallest minority classes
- Previous fairness-oriented approaches: 3% accuracy on minority classes
- DPPL methods: 60% accuracy on minority classes
This represents drastic increases in accuracy on underrepresented groups, with no degradation for majority classes, achieving state-of-the-art results.
Balanced Accuracy of the smallest 25% classes
(CIFAR100, ViT-H-14)
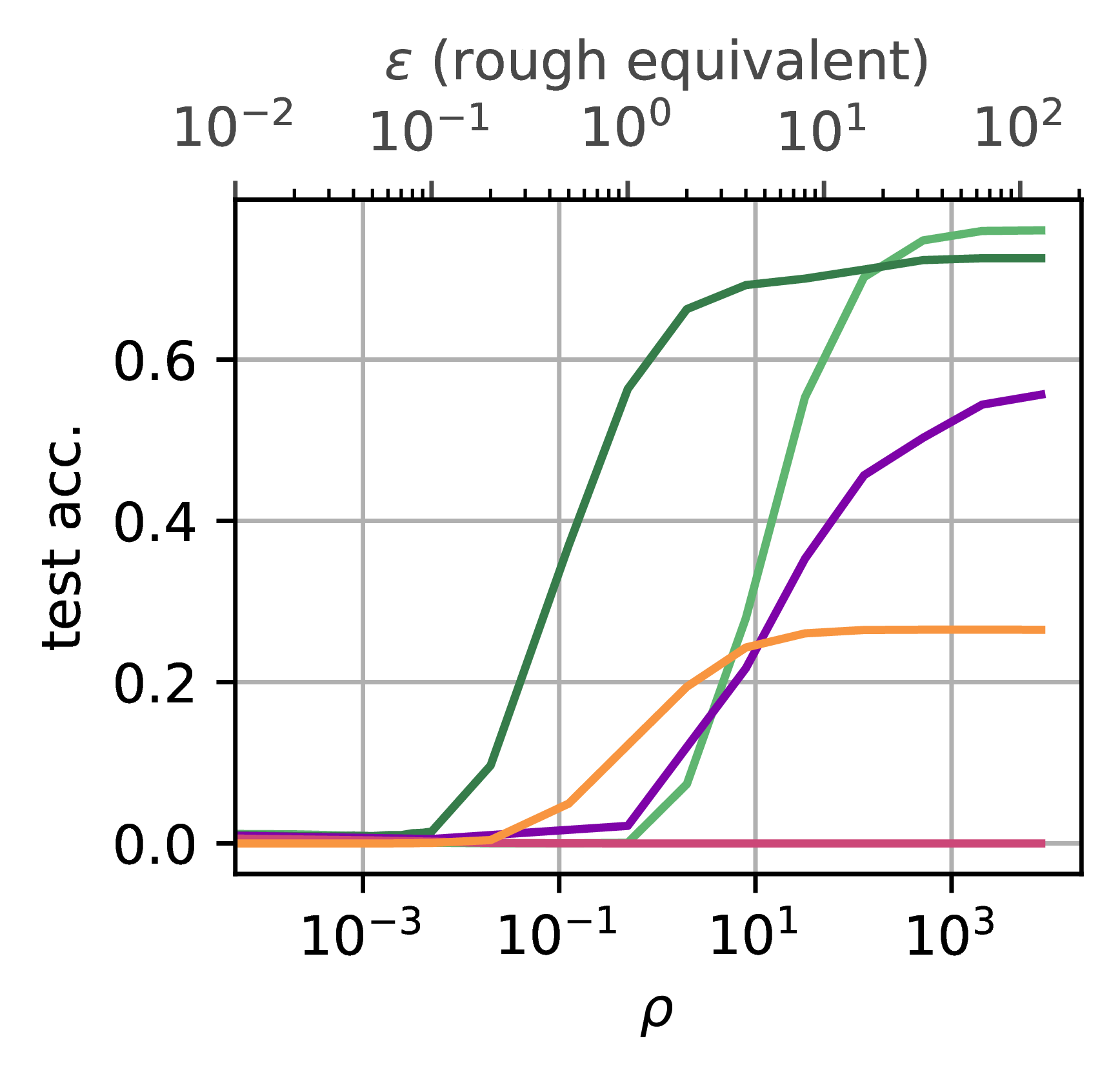

Privacy-Utility Trade-off
Balanced Accuracy (CIFAR100, ViT-H-14)
DPPL methods maintain high accuracy even at very strict privacy budgets (), significantly outperforming DP-SGD in this regime. As increases, the performance gap narrows, but DPPL methods remain competitive across all privacy settings. The results above show performance on CIFAR100 using the ViT-H-14 encoder with 10 samples per class.
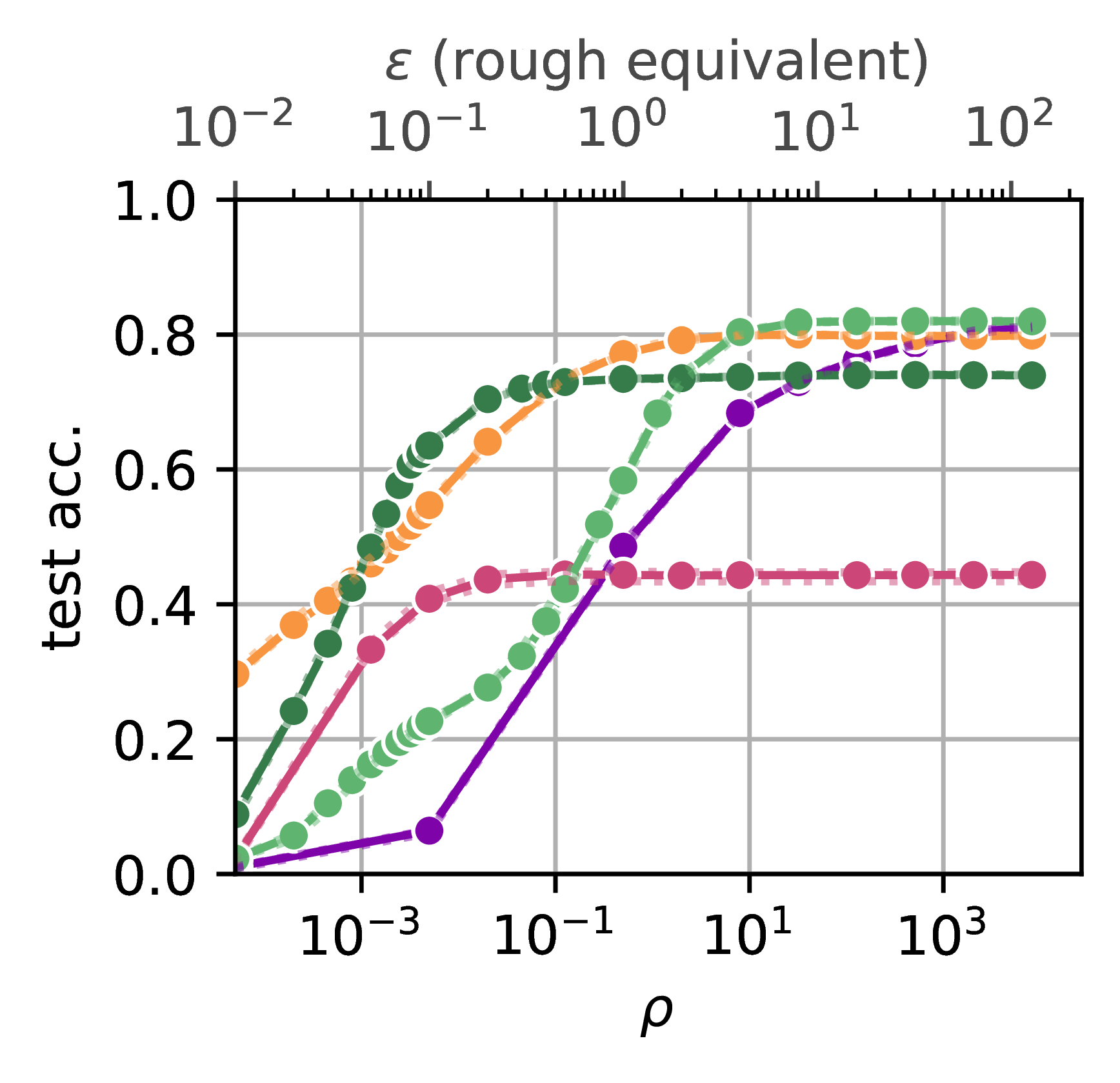
Performance on Imbalanced Data
Balanced Accuracy (CIFAR100, ViT-H-14)
DPPL methods show remarkable robustness to class imbalance. Even with extreme imbalance ratios of 100:1 between the most and least represented classes, the accuracy drop is minimal compared to balanced datasets. This is a significant advantage over traditional methods that struggle with imbalanced private data. For the CIFAR100 dataset with the ViT-H-14 encoder, DPPL methods maintained over 85% of their accuracy when trained on highly imbalanced data, while DP-SGD approaches lost significant performance.