Method: Differentially Private Prototype Learning
Presented at AAAI25, the 39th Annual AAAI Conference on Artificial Intelligence, Philadelphia
Overview
Differentially Private Prototype Learning (DPPL) is a new paradigm for private transfer learning that addresses limitations of traditional approaches like DP-SGD, especially in high privacy, low data, and imbalanced data scenarios.
The key insight of DPPL is to leverage publicly pre-trained encoders to extract features from private data and generate differentially private prototypes that represent each private class in the embedding space.
These DP prototypes can be publicly released for inference while maintaining strong privacy guarantees, even under the notion of pure DP. The approach is particularly powerful as it can generate high-quality prototypes from just a few private training data points without requiring iterative noise addition.
The Privacy-Fairness Dilemma
Traditional differentially private machine learning methods face a fundamental challenge when dealing with imbalanced datasets. The standard approach, DP-SGD, adds noise to gradient updates during training. However, this process disproportionately affects underrepresented groups:
- Different gradient directions: Minority data points often point in different directions than majority data
- Larger minority gradients: With fewer examples of minority groups, the model makes bigger errors on these points, leading to larger gradients
- Disproportionate clipping: When we clip gradients for privacy, minority gradients get clipped more often, systematically rotating the overall gradient toward the majority group
DPPL addresses this bias amplification problem with a prototype-based approach that treats majority and minority classes equally, ensuring both privacy and fairness.
DPPL-Mean
DPPL-Mean takes the most direct approach to creating private prototypes. After extracting features from private data using a pre-trained encoder, it computes a differentially private mean for each class.
Algorithm
- Extract features from private data using a pre-trained encoder
- Apply optional average pooling to reduce dimensionality
- For each class, compute a differentially private mean using the naive estimator:
- Clip each feature vector to control sensitivity
- Compute the mean of the clipped vectors
- Add calibrated noise to achieve differential privacy
- Use the resulting class prototypes for classification
Mathematical Details
1. Feature extraction:
2. For each class c:
a.
b. Optional: Apply average pooling with k_pool to reduce dimensionality
c. Clipping:
d. Compute DP mean:
This method provides a privacy guarantee of ρ-zCDP per class. The clipping parameter r controls the sensitivity, and the privacy cost is ρ for the entire private dataset due to parallel composition across classes.
DPPL-Public
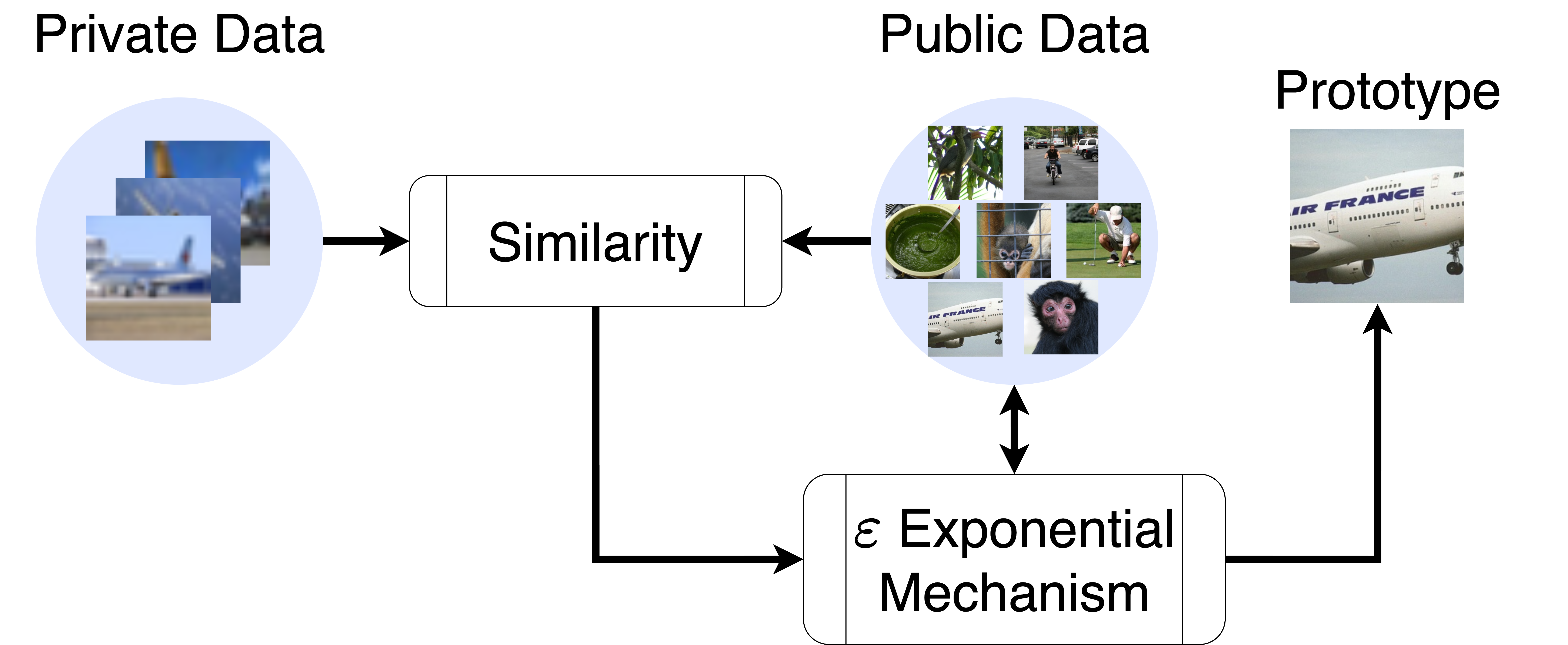
DPPL-Public leverages public data beyond pre-training the encoder. Instead of generating synthetic prototypes, it privately selects the most representative samples from the public dataset to serve as prototypes for each private class.
Algorithm
- Extract features from both private and public data using the same pre-trained encoder
- For each class in the private data, calculate a score for each public sample:
- Compute the cosine similarity between the public sample and each private sample in the class
- Clip the similarities to control sensitivity
- Sum the clipped similarities to get an overall score
- Use the exponential mechanism to privately select a public sample as the prototype for each class
- Use the selected public samples as prototypes for classification
Mathematical Details
1. Feature extraction:
2. For each class c:
a.
b. For each public sample :
c. Select prototype:
This method provides ε-DP guarantees through the exponential mechanism. The utility function is positively monotonic with respect to the private data, and parallel composition applies across classes. The sensitivity is controlled by the clipping parameters d_min and d_max.
DPPL-Public Top-K
DPPL-Public Top-K extends DPPL-Public by selecting multiple (K) prototypes per class instead of just one. This enhances the representation capability, particularly for classes with multimodal distributions or high intra-class variability.
Algorithm
- Calculate scores for public samples as in DPPL-Public
- Sort public samples by their scores in descending order
- Use a private top-K selection mechanism to select K prototypes:
- Privately select one prototype using the exponential mechanism
- Uniformly sample the remaining K-1 prototypes from those with higher utility than the sampled one
- Use all selected prototypes for classification
Mathematical Details
1. Calculate scores as in DPPL-Public
2. For each class c:
a. Sort public samples by score:
b. Define utility U as: (utility of top-k elements)
c. Use exponential mechanism to sample one utility value
d. Uniformly sample remaining K-1 prototypes with higher or equal utility
DPPL-Public Top-K can achieve a slightly higher performance than DPPL-Public, albeit with a higher privacy cost. In those regimes DPPL-Mean is usually already better.