Differentially Private Prototypes for Imbalanced Transfer Learning
Dariush Wahdany, Matthew Jagielski, Adam Dziedzic, Franziska Boenisch
A novel approach that provides strong privacy guarantees while maintaining high utility, even with imbalanced datasets and in low-data regimes.
Machine learning models are trained on vast amounts of data, often scraped from across the internet. This creates serious privacy concerns:
- Models can memorize training data and leak it during inference
- Personal information can be exposed without consent
- Even seemingly anonymous data can be reconstructed
Differential Privacy (DP) offers a mathematical guarantee that individual data points cannot be recovered from a model. However, existing DP methods like DP-SGD come with significant drawbacks.
Differentially Private Prototype Learning (DPPL) is a new paradigm that achieves both privacy and fairness in machine learning:
- Leverages publicly pre-trained encoders
- Generates DP prototypes that represent each private class
- Can be obtained from few private data points
- Offers strong privacy guarantees under pure DP
- Treats majority and minority classes equally
- Eliminates bias amplification inherent in gradient-based methods
By using a prototype-based approach rather than gradient-based learning, DPPL naturally avoids the fairness problems of traditional DP methods, while still providing strong privacy guarantees.
Learn how DPPL works →This demo visualizes privacy-preserving prototypes generated from CIFAR-10 image embeddings using ViT-H/14. The data points shown are 2D projections created using t-SNE dimensionality reduction from the original high-dimensional embedding space.
⚠️ Disclaimer: This is a simplified demonstration for visualization purposes. The privacy guarantees shown here are not rigorous as the t-SNE transformation and other aspects of this demo do not satisfy formal differential privacy requirements.
Good Prototypes
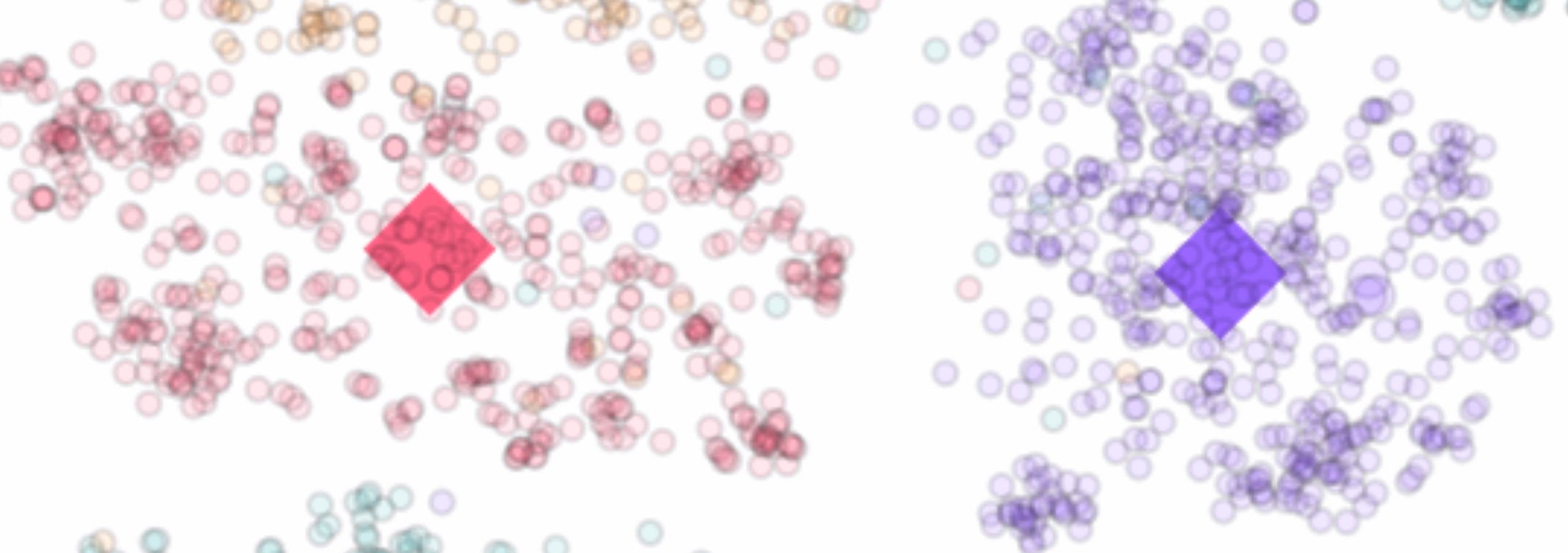
Good prototypes (squares) are well-centered within their class embeddings (dots), effectively representing the class distribution.
Bad Prototypes
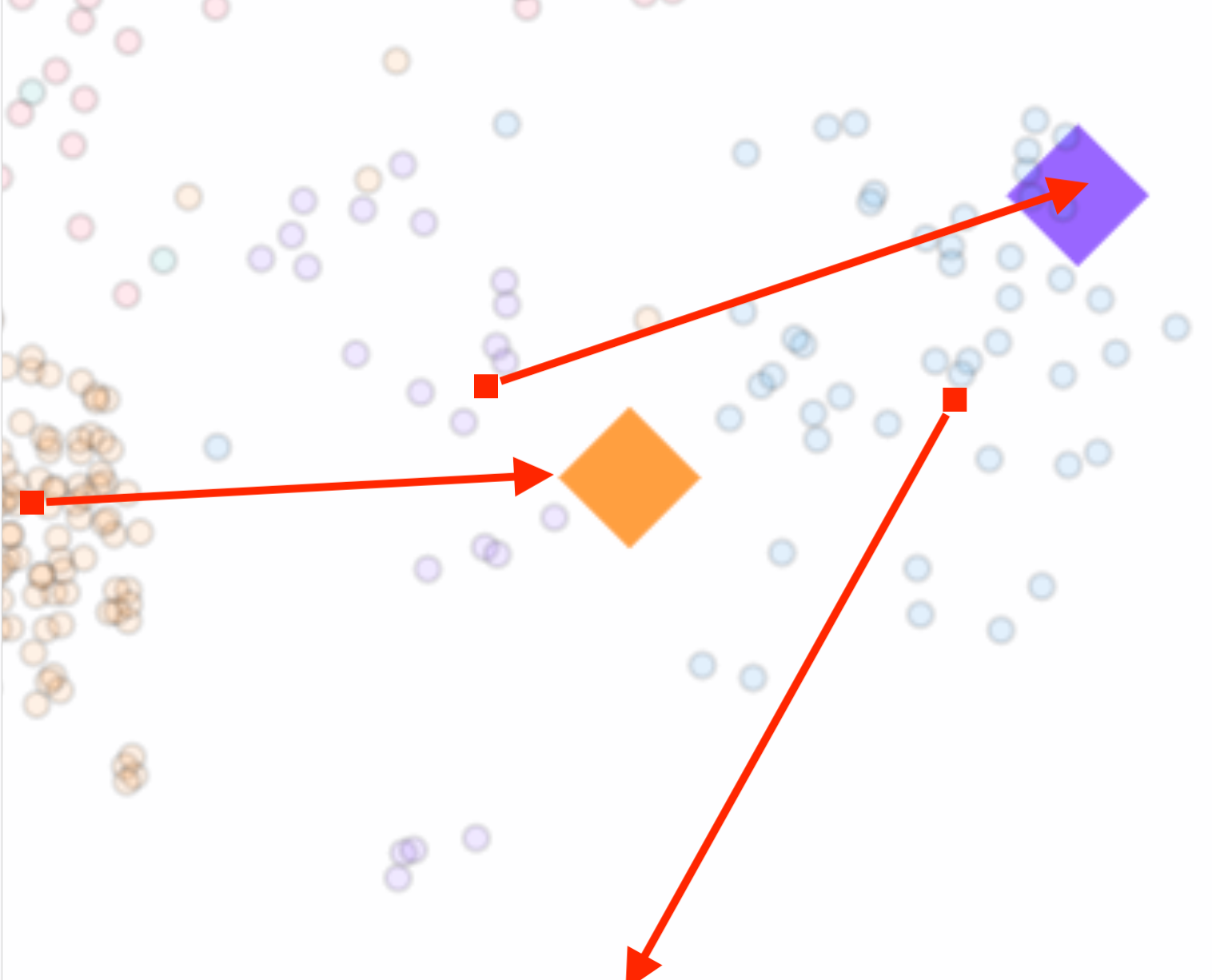
With too strict privacy budgets (small ε), excessive noise pushes prototypes away from their class centers, reducing their effectiveness.
Applies private mean estimation to class prototypes, using a naive estimator with careful calibration of privacy noise.
Learn more →Identifies prototype candidates from public data, using a private selection mechanism to choose the most representative samples.
Learn more →Extends DPPL-Public by selecting multiple prototypes per class to improve representation and utility.
Learn more →DPPL increases accuracy at on minority classes from 0% (DP-SGD) or 3% (DPSGD-Global-Adapt) to 60% — a improvement with no performance degradation for majority classes.
DPPL provides high-utility predictions even under strong privacy guarantees () and with pure DP.
Our methods maintain high performance even with imbalance ratios of 100:1 between the most and least represented classes.
DPPL works with very few private data points per class, making it suitable for low-data regimes where traditional methods fail.
DPPL demonstrates that privacy and fairness can coexist in machine learning systems without sacrificing model utility. By using prototype-based learning with carefully designed privacy mechanisms, we ensure fair performance across all demographic groups, even highly underrepresented ones.
As AI continues to shape society, approaches like DPPL are essential for ensuring that technological progress benefits everyone equally while respecting fundamental rights to privacy.